Hi, I am Christophe. Welcome to my blog! Each month, I will highlight (1) a startup I believe in, (2) a fundraising round that excites me, (3) a tool I started using, (4) an AI research paper I find interesting, (5) an inspiring person I met, and (6) a quote that inspires me. Dive in and enjoy the journey! 🚀
TL;DR
Startup: Adaptive ML - The AI Tailor for Every Business.
Fundraising: Mistral AI - €600 million of funding for Europe’s AI hopes.
Tool: Hugging Face - The Swiss Army knife of AI.
Paper: MatMul-free Language Modeling - Who needs matrix multiplications?
Person: Marc Andreessen - From creating the browser to lobbying AI.
Quote - "You cannot control the wind, but you can adapt your sails."
Startup of the month: Adaptive ML

Overview of Adaptive ML
This month’s company of the month is Adaptive ML. Adaptive ML came out of stealth-mode in March with the announcement of a $20m seed round led by Index Ventures and including notable investors such as US-VC ICONIQ and the investment vehicles of French billionaire Xavier Niel and Hugging Face founder Clément Delangue [2]. Adaptive’s founding team, consisting of ML engineers from Hugging Face and AWS, comes with significant ML experience having contributed to open-source models like Falcon and Bloom. The French-American company will be headquartered in New York City while also having headcount in Paris, France where it is currently setting up a R&D lab [3].
In the last few years, we have seen incredible advancements in frontier AI research, making AI models better, faster, and cheaper. Adaptive ML is here to initiate the next stage in the technology adoption curve, helping early adopters to leverage AI for “more intuitive, stickier genAI applications, directly driving improved user experience and business outcomes”.
The problem statement is the following: To date, one of the main topics in the corporate boardroom is AI. But only a handful of companies have been able to get business value out of GenAI-powered applications. According to Adaptive, this is because pre-trained foundational models are generic “one-size-fits-it-all” solutions that do not serve individual use-cases. While frontier research provides a framework, i.e., reinforcement learning, to align LLMs to human preferences, this family of methods is inherently complex to implement, making it hard for companies without top-tier AI talent and resources to perform preference-tuning. Adaptive’s vision is to empower every company to align their language models to their own preferences, allowing them to build personalized models for its use-cases and customers. They word this as:
Privately tune and deploy open models using reinforcement learning to achieve frontier performance
To do so, Adaptive takes it even further than just upfront instruction tuning or reinforcement learning. They envision that AI models will also be continuously aligned to human preference in production based on human or AI feedback. For users to unlock the power of preference-tuning, Adaptive launched their Adaptive Engine platform. The platform’s capabilities can be clustered in 3 categories:
- Engineering: Reinforcement learning from human/AI feedback (RLHF/RLAIF) methods like Proximal policy optimization, Direct policy optimization, and REINFORCE are everything else but straightforward to implement. And even if companies have the talent and the resources to implement preference-tuning methods, training can cause even more problems due to strong sensitivity to hyperparameters that condition convergence [7]. Adaptive’s Adaptive Harmony API, which is also internally used for research and development, allows to use of these RL frameworks in a highly modular fashion with just a few lines of code, taking care of the tedious distributed training process. Adaptive Harmony is the core piece of the Adaptive Engine.
- Data: Companies tend to deploy GenAI with humans in the loop who make the final decision about whether or not to accept a suggestion [8]. While this helps to prevent hallucinations, Adaptive finds, it also yields valuable data that can be used to improve the underlying model using preference-tuning. Adaptive Engine allows to leverage data from user interaction and even to create synthetic data based on user interactions for additional model alignment.
- Deployment: At the end of the day, Adaptive wants to help businesses use AI models to their advantage. To do so, Adaptive Engine simplifies the collection of relevant business metrics, A/B testing, and finding the right model parametrization (rightsizing).
All this is bundled up in a single software package that clients can quickly deploy in their cloud environment. According to their pitch deck, Adaptive is hoping to be able to charge customers $120k-$360k per year for ongoing use of its platform and up to roughly $1m for custom models [2].
Fundraising of the month: Mistral AI

Mistral AI
As a frenchmen, I was thrilled to hear about Mistral AI closing a massive Series B funding round, raising €600 million (equity + debt) at a $6 billion valuation! [11] The money comes from existing and new investors, including heavy-hitters like General Catalyst, Lightspeed Venture Partners, Cisco and Nvidia [12]. Mistral AI, a company found only about a year ago, is positioning themselves as the European counterpart to the leading foundation model companies, like OpenAI and Anthropic.
Their core values? Open-source and fast execution. Like the ex-employer of two of the three co-founders, Meta, Mistral advocates for open-sourcing AI. The mode behind this positioning is that:
(1) AI is a technology that powerful that everyone should be able to access and customize it to his needs
(2) having only a handful closed-source companies that control all foundational model hinders innovation and yields security issues
(3) the open-source community can make valuable contributions to accelerate AI research
Furthermore, one reason why the three co-founders Arthur Mensch, Guillaume Lample, and Timothée Lacroix left their previous employers was that they were frustrated by their operation speed and bureaucracy. This is why Mistral is build on the foundation of small, incredibly smart teams that work in silos. The had the following comment on its culture:
“We go fast and work intensely, with high level of individual responsabilities, and a strong team spirit”
Mistral got first known with their 7 billion parameter open-source models Mistral 7B. Soon after, the company made waves through the AI community making first use of the sparse model of experts (SMOE) architecture to build their next biggest model Mistral 8x7B and Mistral 8x22B. Not only were the models amongst the first to perform comparably well to the best closed source models (Mistral 8x7B beats GPT3.5 across most benchmarks [16]) but they are also, thanks to the SMOE architecture which uses much less (only two out of 8 experts) parameters during inference, cheaper than other existing models. On top of that the company recently launched their API, La Plateforme, a model for code generation, Codestral, and a chat web application, Le Chat. They recently also launched a fine-tuning API on La Plateforme.
Recently, after launching a set of enterprise closed source models and removing “committing to open models” from their website [21], Mistral faced some backlash from the open-source community as it seems the like the company is overthinking their commitment to open-source. My point of view on this is that even though Mistral is committed to building open-source frontier AI models, they still have to make money, especially after collecting millions of dollars from investors. Monetization of open-source AI software is mostly done through hosting and customer support but as companies start building their own AI teams, these options seem less and less lucrative. Thus, building up some cash flow to finance those H100 GPUs by building a range of enterprise models definitely makes sense to me. It would just be sad to see Mistral building their newest innovations into the closed source models whilst using the open source models only as a PR campaign.
Tool of the month: HuggingFace
Overview of models on the HuggingFace hub
I am well aware that this is not a hidden gem, HuggingFace has been around for quite some time now and is probably the most well known developer tooling platform for ML practitioners. Yet, I recently started a little side project which included fine-tuning the Mistral-7B-Instruct model using QLoRA and after doing so with HuggingFace’s Transformer Reinforcement Learning (TLR) library, I feel like I used the full breadth of HuggingFace for the first time.
HuggingFace is a French-American company founded in 2016 in New York City by French entrepreneurs Clément Delangue, Julien Chaumond, and Thomas Wolf. Some see the company as the godfather of the AI open-source movement and with it’s 1000s of lines of open-source code and hubs full of open-source AI resources it has certainly turned into the heart-piece of this continuously growing community. Driven by the thought of creating “The AI community building the Future”, the company named after a smiley offers open-source tooling and resources for ML Engineers. This includes:
- Resources: Resources includes machine learning models, datasets, spaces, and a community forum. The resources are available on the HuggingFace Hub via embedded GitHub repositories. All resources are open-source and freely available for all users with a HuggingFace account via the
huggingface_hublibrary.- Models: Every member of the Hugging Face community can host model checkpoints (entire models or model state dicts) for simple storage, discovery, and sharing on the hub. By now, there is already a whopping 735,742 models on the hub. This includes the most prominent and powerful open-source models like Meta's Llama-3-70B-Instruct and Mistral’s Mixtral-8x22B-Instruct.
- Datasets: Datasets is an open-source library of 168,596 datasets for Audio, Computer Vision, and Natural Language Processing (NLP) tasks. Datasets can easily be downloaded with only a single line of code and the Apache Arrow engine ensures efficient handling of large-scale datasets. With 16.1 milion downloads, a notable example for a dataset on the HF Hub is the Measuring Massive Multitask Language Understanding dataset, the dataset behind the prominent MMLU benchmark to evaluate large language model.
- Spaces: Spaces allow to host ML demo apps directly on the Hugging Face hub to showcase personal/professional projects and to work collaboratively with other people. Spaces support Streamlit and Gradio to deploy apps with only a few line of Python but can also handle Docker for more sophisticated work. By default, Spaces run on two free CPU virtual machines with a combined 16GB of RAM and 50GB disk. If needed, this can be upgraded and there are even GPUs available (up to 8xNVIDIA H100 👀). With over 10,400 likes, the Open LLM Leaderboard 2 is the second most liked space over all. This leaderboard for LLMs was one of the first ones publicly available. It allows to evaluate models in a standardised fashion (same questions, asked in the same order, etc.) to enhance reproducible and comparable results. Over time, this leaderboard became widely popular, visited by more than 2 million unique people over the last 10 months. The evaluation of models is performed on knowledge testing, reasoning on short and long contexts, complex mathematical abilities, and tasks well correlated with human preference based on six different high-quality benchmark datasets [39]
- Community forum: Last but not least, the hub hosts a Posts section where the open-source AI community can share, discuss, collaborate, and learn together. This encompasses posts, guides, learning materials (e.g, courses), and forums.
- Tooling: HuggingFace complements Hubs with an extensive set of tools for AI engineers to efficiently use the resources on the hub and facilitate the access to complicated AI algorithms in general, first and foremost the infamous Transformers transformers library. To date, HuggingFace has accumulated over 30 libraries for diverse use-cases of AI engineers (find overview here) including working with deep learning frameworks (Pytorch, TensorFlow,…), diffusion model, ML demos, parameter efficient fine-tuning, tokenizer, model evaluation, reinforcement learning, quantization, and more. With over 128k stars the transformer library, the most popular HuggingFace library, belongs to the top 10 most starred repos on GitHub of all time. The library introduces a framework-agnostic tool to access and train (pre-trained) AI models. This includes all kinds of ML subdomains like NLP, Computer vision, audio, and multimodality. While there are too many classes and functionalities assembled in this library to mention them all, I would like to outline Auto Classes which has been a real gamechanger, breaking down entry barriers to build stuff with AI for non-professionals. Auto Classes include AutoConfig, AutoTrain, and AutoTokenizer, three classes that allow to standardize preprocessing, training, and inference of deep learning models for all kinds of architectures. This is incredibly helpful as every developer and ever company has their own specificities, making changing from one architecture to another a cumbersome process. With transformers, I can easily replace my model, e.g., replace Llama with Mistral, just by changing a few lines of codes, allowing me to use the right tokenizer and hyperparameters without having to change the logic of my codebase. From a business perspective, HuggingFace’s stellar success as an open-source platform has also fueled the growth of the AI startup [45].The company recently raised a $235 million in a Series D funding round. The investment with participation from Google, Amazon, Nvidia, Intel, AMD, Qualcomm, IBM, Salesforce and Sound Ventures, values Hugging Face at $4.5 billion. That is double the startup’s valuation from a year before and reportedly more than 100 times Hugging Face’s annualized revenue, reflecting both the enormous appetite for AI and platforms to support its development but also the known conundrum of translating buzz into bucks as an open-source business. Nevertheless, today, the company has 10,000 customers already and it claims to have more than 50,000 organizations on the platform. Personally, I am a big advocate of open-source AI software and I think open-source, and thus, HuggingFace, will dominate the future of the AI industry. Although, it remains to be seen how HuggingFace can diversify their revenue streams beyond infrastructure hosting.
Paper of the month: Scalable MatMul-free Language Modeling
Alright, let’s get our hands dirty and dig a little bit into the latest developments in AI research. One recent paper that caught my attention this month is Scalable MatMul-free Language Modeling. In this paper Zhu. et al. present a transformer model that operates without engaging any Matrix Multiplications (MatMul). In a comparison with Transformer++ (based on Llama2) across models of up to 13B parameters scale, the researchers find a 61% memory reduction during training, a 25.6% speedup in inference time, and 10x less memory consumption during inference [47]. Furthermore, they indicate that the scaling laws (decrease of the model error as a power function of training set size and model size) of this architecture might be even steeper than the ones of traditional transformer architectures. This might seem like a tedious change but considering the tremendous amount of time, money, and energy spend on training and inference of large-scale transformer architectures today, this novel architecture yields enormous potential to increase the efficiency of such systems. To give you an idea, it is rumoured that GPT4 was trained on 25,000 Nvidia A100 GPUs for 90–100 days (assumptions based on unverified leaks on GPU 4 training setup [48]). Based on reasonable assumption that would imply over $100m of training costs [49], 51,772,500 to 62,318,750 KWh of electricity consumed, and 12,456 of 14,994 metric tons CO2e emitted [50]. Now you can do the math how much money, time, and energy could be saved if such metrics translate into reality.
Zero-shot performance on benchmark datasets such as ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA, and OpenbookQA demonstrated competitive results, with the largest MatMul-free model sometimes outperforming its Transformer counterpart. Additionally, the MatMul-free models exhibited significant improvements in training and inference efficiency (61% reduction in memory usage during training andmore than a 10× reduction during inference, with training speed improvements of 25.6%). The authors pushed it even further an customized their own field programmable gate arrays (FPGAs), programmable integrated circuits, to run the model which demonstrated the potential for substantial speed-ups and reduced power consumption. Overall, a very exciting finding, I would love to see how this scales for larger models. Check it out on your own, the model is available here. Today’s transformer architecture heavily relies on MatMul as multi-layer perceptrons (MLPs) encompass vector-matrix multiplication (VMM) and self-attention layer encompass matrix-matrix multiplication (MMM). Even though Nvidia’s Compute Unified Device Architecture (CUDA) and Tensor cores [51] allow for optimized MatMul operations, MatMul are still complex operations that take up most of the training time and memory for deep learning models due to extensive data movement and synchronization efforts on GPUs. Although creating a MatMul-free Transformer has been attempted before (BitNet), prior work lacked in performance, convergence, and scale. The main trick to create MatMul-free Transformer while maintaining similar performance is to quantitize the weight matrices involved in MLPs and self-attention to 1bit/1.58bit precision to represent every single wait with binary (1) or ternary values (1). This allows to transform a matrix multiplication into computationally cheaper operations, i.e., signed addition. Say we have an MLP layer that takes a vector as an input and outputs . We can express the forward step as:
where represents the trainable weights of the MLP. If we quantize the weights into ternary values , we can simplify this to
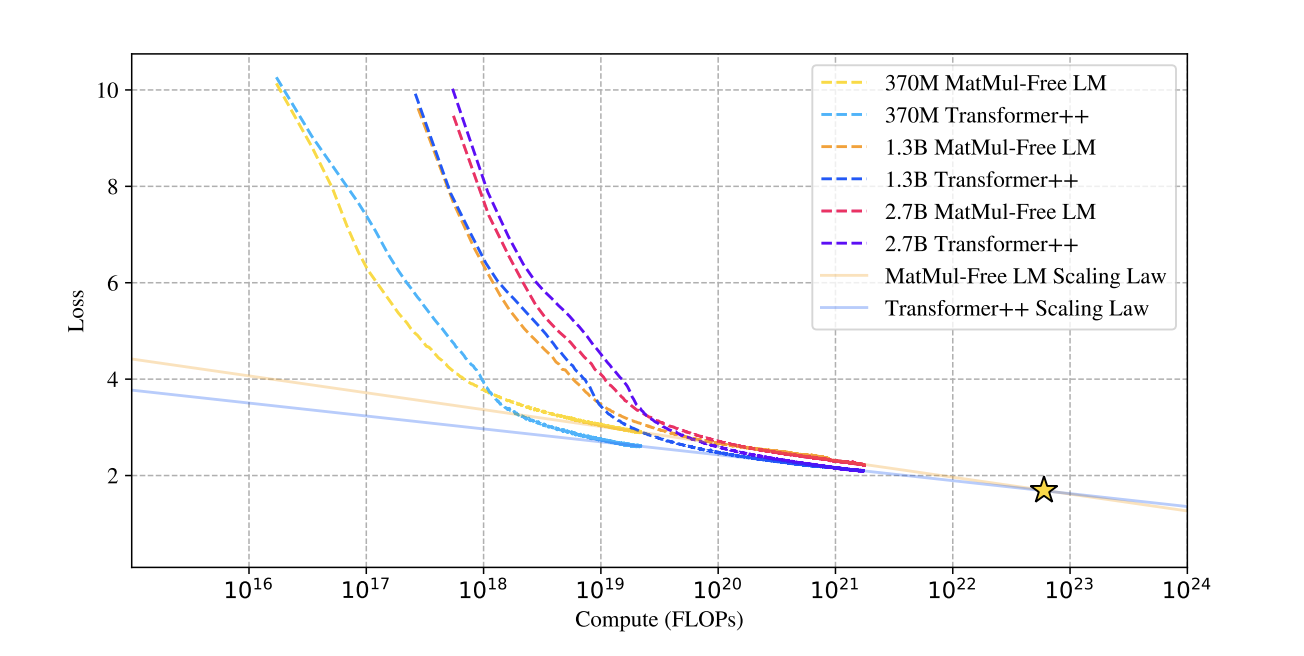
Interestingly simply substituting the original MLP and self-attention layer with such quantized components is not sufficient as it has been observed that efficient training of quantized networks is not straightforward [53]. To replace MLP with similar well-performing MatMul-free layer, the authors of BitNet [54] found that one has to add Root-Mean-Squarre Normalization (RMSNorm RMSNorm) layer before the layer input. The authors have adapted forward pass and back-propagation accordingly. To make the self-attention mechanism MatMul-free, even more adaptations are necessary since the authors found Transformers with quantized query and key matrices are not converging [56]. Adopting the Metaformer framework, which assumes a transformer consists of two modular, exchangeable components, the tokenmixer (i.e., MLP) and a channel-mixer (i.e., self.attention), recurrent neural network (RNN) components have been identified as good alternative for the self-attention mechanism as channel-mixer. Gated Recurrent Units (GRUs), a component also used in LLama and Mistral as channel-mixer, turns out to be a good working solution. By simplifying the architecture to make it parallelizable and by applying the previous quantization step to all remaining weight matrices, we get Gated Linear Unit (GLU), a MatMul-free channel-mixer. he authors conducted a series of tests with the MatMul-free Language Model, comparins the model with a the Llama-based Transformer++ model of in the sizes 370 million, 1.3 billion, and 2.7 billion parameters. These models were pre-trained on the SlimPajama dataset, with smaller models trained on 15 billion tokens and larger models on 100 billion tokens each. The experiments revealed that MatMul-free models achieved performance on par with state-of-the-art Transformers, with the performance gap narrowing as the model size increased. The scaling curves below even suggest, as mentioned before, that the quantized MatMul-free models learn more efficiently than their MatMul-intensive counterparts.
Overview of models on the HuggingFace hub
Person of the month: Marc Andreessen

Picture of Marc Andreessen and Fei-Fei Li at HAI conference
This month, I am excited to highlight someone who has profoundly influenced me: Marc Andreessen. I recently had the extraordinary opportunity to see him speak live at this year's HAI Five Conference at Stanford. Earlier this month, I had the opportunity to see Marc Andreessen, the co-creator of Mosaic—the first widely used web browser—and the co-founder of Netscape, talk live on stage with the esteemed AI researcher, professor, and co-director of the Stanford Human-Centered AI Institute (HAI) Fei-Fei Li. The insights shared during this fireside chat on “Removing Impediments to a Robust AI Innovative Ecosystem” not only made clear to me how fast Marc talks but also the magnitude and breadth of his impact on pretty much every technological throughout the last 30 years. What some do not know is that Marc Andreessen is not your typical venture capital general partner who did investment banker and went to grad school in Boston. In fact, quite the opposite, Marc started his career as not more than one of the most brilliant computer scientists the world has seen. Born in Cedar Falls, Iowa, and raised in New Lisbon, Wisconsin, Marc earned a bachelor's degree in computer science from the University of Illinois at Urbana-Champaign [65]. It was there that he co-authored Mosaic with Eric Bina, a pivotal moment for the emerging .com industry that marked the inception of his career in tech. Following this, Marc co-founded Netscape Communications Corporation in 1994, which played a crucial role in commercializing the Mosaic browser, effectively paving the way for the modern internet. Marc did not stop there. He went on to co-found several successful ventures, including Loudcloud (later Opsware), Ning, and the influential venture capital firm Andreessen Horowitz (a16z) in 2009. His contributions to the tech industry are monumental, but what truly sets him apart is his unwavering commitment to innovation and relentless pursuit of progress. Despite his significant success, Marc continues to drive innovation through a16z, supporting startups that are shaping the future. At the HAI Five Conference, Marc emphasized the importance of the precautionary principle, advocating for a balanced approach to technological advancement and regulation. He cautioned against overregulation, using Germany's missed opportunities in the energy transition as an illustrative example. His perspective on open-source technology was particularly striking. Marc argued that regulating open-source could undermine human freedom and disrupt the symbiotic relationship between startups, academia, and open-source communities. This viewpoint resonated deeply with me, highlighting his profound understanding of the intricate dynamics that drive technological progress. Marc's techno-optimism stands as a beacon of hope in an era often marked by skepticism and fear of technological change. His Techno-Optimist Manifesto underscores the belief that technology is the engine of progress, capable of addressing some of humanity's most pressing challenges, such as poverty, climate change, and healthcare. Marc's relentless drive to push boundaries and his vision for a better future through technology are genuinely inspiring. In summary, Marc Andreessen's journey from a technical genius to a pioneering entrepreneur, influential investor, and advocate for innovation, is something I admire a lot. His talk at the HAI Five Conference reinforced my belief in the power of technology to create a better world. Marc's dedication to fostering innovation, his insightful perspectives on regulation, and his unwavering optimism make him an inspiring figure and a deserving "Person of the Month" in my eyes. Thank you for reading, and I hope you find Marc Andreessen as inspiring as I do.
Quote of the month

Quote of the month [66]
Recently, a lot has changed for me personally. Beyond my geographical move to the US, leaving, leaving friends and family behind, I have also graduated from my Master’s program at HEC Paris and École Polytechnique, raising the question: What’s next? Ironically, this is also the first time I do not really know what I want to do professionally. A few years ago, I thought to have found my “passion” in strategy consulting but shortly after starting my Master’s in Data Science, this dream vanished and ever since then I basically only know that I would like to work in the field of Data Science. But launch a startup? Join a startup? Do research? I do not really have a clue yet. Although I love being surrounded by smart, ambitious people, like I was in RWTH Aachen, École Polytechnique, and HEC Paris, and like I am at Stanford, seeing everyone around you achieving great things can also make you question yourself and put even more pressure on yourself. And that is why, when I saw this quote on Pinterest earlier this month, it resonated a lot with me. I am not a really religious person and I do not necessarily believe in concepts like destiny but I am a strong advocate of merit-based ideologies such as “you get what you deserve”. In my belief, consistently putting in the work, whatever it might be you put the work “in”, will compound and, eventually, pay off one day. Even if no one sees it and even if it does not yield results immediately. Give it all you have, day in day out, and some day you will be rewarded to it. This is what I understand under “you can adapt your sails”. With your daily decisions, you can line up the sails and decide in which direction the wind is going to blow you. With your daily decisions you can trim or loosen the sails and decide how quickly you are going to go in that direction. So by doing all you can in your daily life, by setting your sail, one can sort of optimizing one’s chances to make it. Whatever that might mean to you on an individual level. The part “You cannot control the wind”, on the other side, implies that how quick you are going to get “there” and on which path, not only depends on you but also on the “wind”. In my opinion, the wind must not necessarily be some higher force in this case. It can simply be luck. Do you meet the right person at the right time? Does your industry blow up all of the sudden?, …. And I interpret even more into this part. Let us adapt the metaphor of a sailor. We all know not only the wind allows the sailor to move forward but the sailor is also depending on the wind to move forward. Furthermore, the sailor cannot necessarily change the winds force or direction. For me, this showed that I also do not, and maybe cannot, get everything I want right now in this moment. The “wind” in combination with my orientation of the sales will help me to achieve all those things, be it personal or professional. Insisting on instant gratification, metaphorically jumping out of the boat to swim to the thing you want most, might not just be unnecessary but maybe even counterproductive in the long run, imagine jumping from the boat in the middle of the ocean to swim to a small island.
References
- https://www.adaptive-ml.com/
- https://sifted.eu/articles/gen-ai-startup-adaptive-20m-seed
- https://www.indexventures.com/perspectives/how-adaptive-is-bringing-genai-alignment-to-the-enterprise/
- https://arxiv.org/abs/1707.06347
- https://arxiv.org/abs/2305.18290
- https://arxiv.org/abs/2010.11364
- https://arxiv.org/abs/2305.18290
- https://www.indexventures.com/perspectives/how-adaptive-is-bringing-genai-alignment-to-the-enterprise/
- https://sifted.eu/articles/gen-ai-startup-adaptive-20m-seed
- https://techcrunch.com/2024/06/11/paris-based-ai-startup-mistral-ai-raises-640-million/
- https://mistral.ai/
- https://techcrunch.com/2024/06/11/paris-based-ai-startup-mistral-ai-raises-640-million/
- https://www.reuters.com/technology/artificial-intelligence/mistral-ai-raises-600-mln-euros-latest-funding-round-2024-06-11/
- https://mistral.ai/news/mixtral-of-experts/
- https://huggingface.co/mistralai/Mistral-7B-v0.1
- https://huggingface.co/mistralai/Mixtral-8x7B-v0.1
- https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1
- https://mistral.ai/news/mixtral-of-experts/
- https://console.mistral.ai/
- https://console.mistral.ai/codestral
- https://chat.mistral.ai/chat
- https://docs.mistral.ai/guides/finetuning/
- https://news.ycombinator.com/item?id=39517016
- https://huggingface.co/
- https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3
- https://arxiv.org/abs/2305.14314
- https://huggingface.co/docs/trl/en/index
- https://www.linkedin.com/in/clementdelangue/
- https://www.linkedin.com/in/julienchaumond/
- https://www.linkedin.com/in/thom-wolf/
- https://huggingface.co/models
- https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct
- https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1
- https://huggingface.co/datasets
- https://huggingface.co/datasets/cais/mmlu
- https://huggingface.co/spaces
- https://streamlit.io/
- https://gradio.app/
- https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
- https://huggingface.co/spaces/open-llm-leaderboard/blog
- https://huggingface.co/posts
- https://huggingface.co/posts
- https://huggingface.co/docs/transformers/index
- https://huggingface.co/docs
- https://huggingface.co/docs/transformers/v4.41.3/en/model_doc/auto#auto-classes
- https://huggingface.co/
- https://arxiv.org/pdf/2406.02528
- https://arxiv.org/pdf/2406.02528
- https://archive.md/2RQ8X
- https://fortune.com/2024/04/04/ai-training-costs-how-much-is-too-much-openai-gpt-anthropic-microsoft/
- https://readcache.xyz/api/p?url=https://towardsdatascience.com/the-carbon-footprint-of-gpt-4-d6c676eb21ae
- https://www.nvidia.com/en-us/data-center/tensor-cores/
- https://arxiv.org/abs/2310.11453
- https://arxiv.org/abs/2302.02390
- https://arxiv.org/abs/2310.11453
- https://arxiv.org/abs/1910.07467
- https://arxiv.org/pdf/2406.02528
- https://arxiv.org/abs/2111.11418
- https://arxiv.org/abs/2307.09288
- https://arxiv.org/abs/2310.06825
- https://arxiv.org/abs/1612.08083v3
- https://github.com/ridgerchu/matmulfreellm
- https://x.com/pmarca
- https://hai.stanford.edu/events/hai-five-celebrating-5-years-impact
- https://www.linkedin.com/in/fei-fei-li-4541247/
- https://www.britannica.com/biography/Marc-Andreessen
- https://www.pinterest.fr/pin/18084835997251949/