Welcome to my first blog! 🎉 Each month, I will highlight a startup, fundraising news, a cool tool, a groundbreaking research paper, and an inspiring person. I will also share a thought-provoking quote and a deep dive into a topic I'm passionate about. Dive in and enjoy the journey through the exciting world of AI and innovation! 🚀
TL;DR
This month, we're highlighting Artisan AI, a startup transforming workflows with AI agents like Ava the Sales Rep. Two AI companies, H Company and The Bot Company, are making waves in fundraising, with H aiming for AGI and The Bot Company creating bots to handle chores. Developers will love Langfuse, an LLM engineering platform with comprehensive features like tracing and analytics. Kolmogorov-Arnold Networks (KAN) offer an exciting alternative to multi-layer perceptrons, catching the attention of top researchers. Sam Altman, our person of the month, inspires with his entrepreneurial journey and belief in AGI's potential. Remember, "Stop trying to be liked by everybody, you don’t even like everybody." Finally, we're diving deep into AI interpretability, crucial for fields like healthcare and finance, with the latest research making AI more transparent. Join me for insights and a peek into AI's future! 🎉
Of the month
In this category, I highlight a few of my highlights of the month across 6 categories: a startup I discovered, a fundraising round I am excited about, a tool I started using, a paper I find ground-breaking, a person I met, and a quote that I found worthwhile.
Startup of the month: Artisan AI

Overview of Artisan AI
This month’s company of the month is Artisan AI (summary slide above). I first discovered the company during this winter’s YC batch (YC W24), but after hearing Jaspar Carmichael-Jack pitch and demo Artisan at this year’s HubSpot GenAI Summit in San Francisco, I had to dig deeper. As someone who spends a lot of time playing around with the newest LLM models and AI tools, which gives me some intuition about what can and cannot be done, I am generally pessimistic about companies building agentic workflows. But I have to admit, the team behind Artisan AI might be on to something.
Agentic workflows
As Andrew Ng underlined at Sequoia‘s AI Ascent, agents are the future of AI. But what are agents and agentic workflows? AI agents are defined as AI systems that can plan, make decisions, and take actions in a pre-defined environment. An example of an AI agent would be an AI system able to build you a PowerPoint pitch deck for your startup based on your description and some context files without you having to open PowerPoint, organize the content of the slides, and so on. Under the hood, the AI system is working itself along an agentic workflow. Today, an agentic workflow encompasses a pre-defined process (e.g., analyzing the context, researching the structure of a pitch deck, structuring the content accordingly, thinking about the layout of the slides, creating the slides, evaluating the slides, etc.) the agent is going through, at every step, evaluating the need for certain actions (e.g., open PowerPoint and add 12 empty slides) and eventually calling other tools to perform these actions (e.g., recurse to the slide layout step for the team slide because it is not easy to understand). Artisan AI has set itself the goal to lead the next Industrial Revolution of human workers by building exactly such agents. At Artisan, you can hire your AI agent like you would hire a human coworker. For now, the company offers three different AI workers: Ava the Sales Representative, Liam the Marketer, and James the Customer Success Representative. These personas are intended to complete tasks humans do in the respective domains end-to-end. Ava, for instance, is capable of taking over your sales outbound at scale. After setting up the worker with information about your company, products, and goals, the sales rep takes over and makes outreaches to thousands of prospective customers on your behalf (do not worry, you can also choose to validate each mail before it is sent) based on a database of contacts. Not only does Ava send these emails using effective sales best practices, but she can also follow up and schedule meetings with your human sales team (AI bots are not allowed to conduct video calls yet).
Agents need an OS and Artisan can provide it
What sets Artisan apart is that they are not only providing the agents as standalone solutions but also the operating system (OS) allowing the orchestration of these agents. When you think about it, that makes a lot of sense. Even human workers have to be onboarded on how the job works, get to know the company’s products and services, get access to all the tools they need, get to know the company’s values, and understand their goals and goal metrics. For AI workers, setting this “context” is even more important so this is exaclty what you can do on Artisan's OS platform. Today’s AI systems are still not very good at reasoning, so the more context you provide, the better an AI system can fulfill its tasks as you intended it to, hence maximizing the alignment of the worker with your company. Furthermore, the Artisan platform allows you to communicate with your worker, like you would with a human employee, to get insights into what they are doing and give them instructions. All that is complemented with analytics dashboards and third-party app integrations.
Fundraising of the month: The bot company and H
Exceptionally, this version of the blog will contain two companies in this category because I could not omit mentioning either of these companies.
As a French citizen, there was no way H would not be mentioned in this category. H, a Paris-based company previously known as Holistic AI, just announced their massive $220m seed round with notable investors including venture firm Accel, Creandum, and Visionaries Club; tech giants Amazon and Samsung; and investors Xavier Niel and Bernard Arnault . Charles Kantor, previously a researcher at Stanford University, along with his four co-founders from DeepMind, will be the CEO of this venture with the goal to build “frontier action models to boost the productivity of workers”. I am really excited about this new Paris-based AI giant striving for AGI.

Vision of H [4]
It seems like serial entrepreneur Kyle Vogt never misses. After successfully co-founding Twitch and the self-driving car company Cruise, he has now announced his next venture on Twitter, the robotics startup “The Bot Company.” Investors seem confident in the company Vogt is co-founding with Paril Jain (Ex-Head of Planning at Tesla) and Luke Holoubek (Ex-Cruise), providing the company with $150 million of funding. The company’s vision? “We're building bots that do chores so you don't have to. Everyone is busy. Bots can help.”
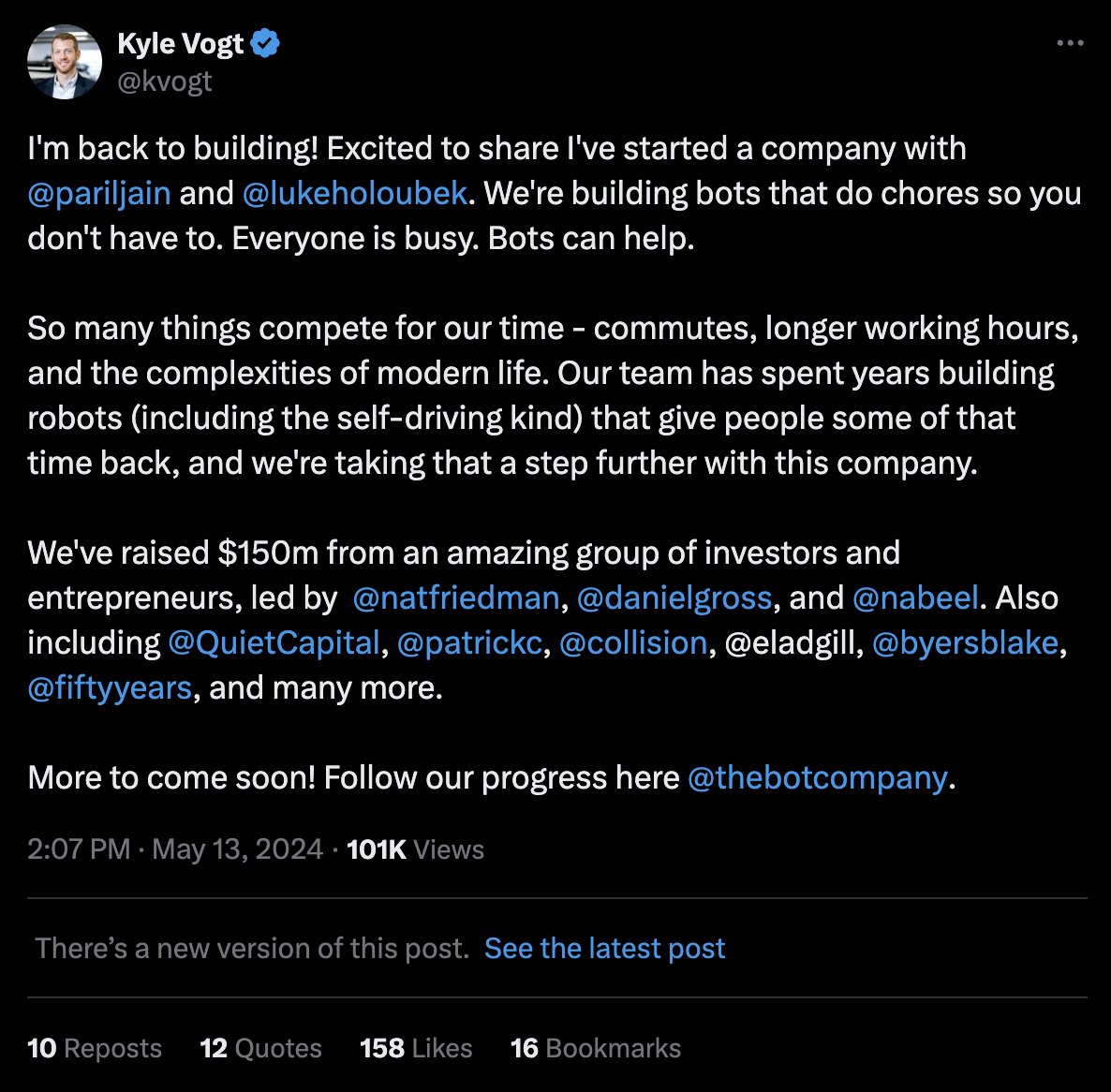
Tweet announcement of the Bot Company [6]
Tool of the month: Langfuse
I may be a little biased here, but this one is a no-brainer for me. Langfuse, a Y Combinator company out of the winter 2023 batch, is an LLM engineering platform helping developers shed some light on their LLM applications. The core feature of the open-source developer tool is tracing, which allows developers to log LLM (application) calls step by step. For every component inside their LLM application, including the LLM API call, relevant information such as input, output, and parameters are logged. These logs, inspired by OpenTelemetry, are then visualized in the Langfuse app (see image below).
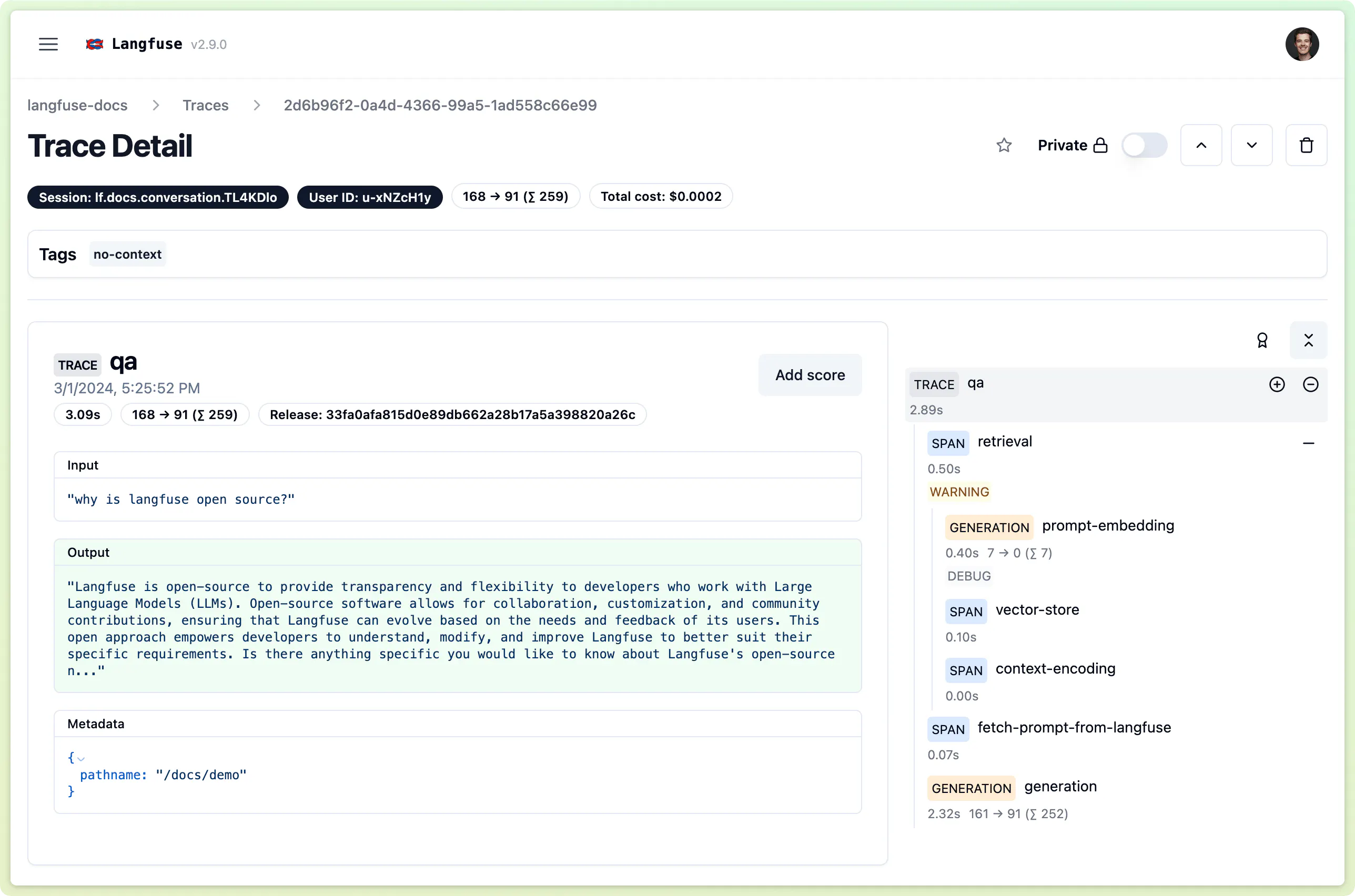
Example of using Langfuse for tracing a RAG application [8]
On top of this foundation, the co-founders, Marc, Max, and Clemens, built a set of features to help developers build better LLM applications:
- Analytics: Gain insights into your LLM application in production by tracking metrics such as costs, latency, and token volume in real-time.
- Prompt managemnt: Manage and version prompts and their configuration (for function calls) in production.
- Playground (Beta): Test and iterate on prompts to observe changes in model behavior before putting them in production.
- Evals (Beta): Langfuse supports manual and model-based evaluation of LLM application calls. The former method allows users to manually score LLM generations. The latter, currently in beta, allows developers to automatically evaluate the outputs of their LLM application in production leveraging another LLM.
- Datasets: Collect traces of inputs and (expected) outputs of your LLM application in production in datasets to test changes in your application on these datasets. In combination with prompt management and evals, this feature is a game-changer for LLM app developers.
The tool is free by default (up to 50k observations) and there are pro and team tiers for more sophisticated use cases (>=100k observations, dedicated support, and beta access).
This suite of features, paired with their incredible UI and the easy-to-use Python decorator integration, makes this my go-to tool for every LLM application I build. I am looking forward to having all these features (especially datasets, prompt management, playground, and evals) seamlessly integrate with each other, and I am very curious about what the future holds for Langfuse as the AI space expands.
Paper of the month: Kolmogorov-Arnold Networks (KAN)
This is where we get a little bit more technical. Researchers from MIT, Caltech, Northeastern, and the NSF Institute for AI released the paper KAN: Kolmogorov-Arnold Networks earlier this month. KANs, if proven to scale well, are a promising alternative to multi-layer perceptrons (MLPs), the fundamental component of most deep neural networks.
where and .
Kolmogorov-Arnold representation theorem
Today’s MLPs are based on the universal approximation theorem, which states that, in a specific region, every function can be modeled by a function where is parametrized by an MLP with non-linear activations (e.g., ReLU). This attribute is responsible for most of the capabilities of modern DNNs. Yet, MLPs are also computationally expensive (approximating complex functions can need lots of layers and neurons) and opaque due to non-linear activation functions [15]. For many years, researchers have tried to build an alternative model architecture leveraging the Kolmogorov-Arnold representation theorem. This theorem basically postulates that every multivariate continuous function can be modeled by a finite composition of univariate functions and the sum operation (see formula above) [16], potentially paving the way for more powerful and interpretable architectures. The problem to date was that the theorem models KANs as two-layer networks with 2𝑛+1 (where 𝑛 is the input dimension) nodes in the hidden layer. Reformulating the theorem to scale this architecture to "wider and deeper" networks is what led to a significant performance boost, as this paper shows. But what does this network finally look like?
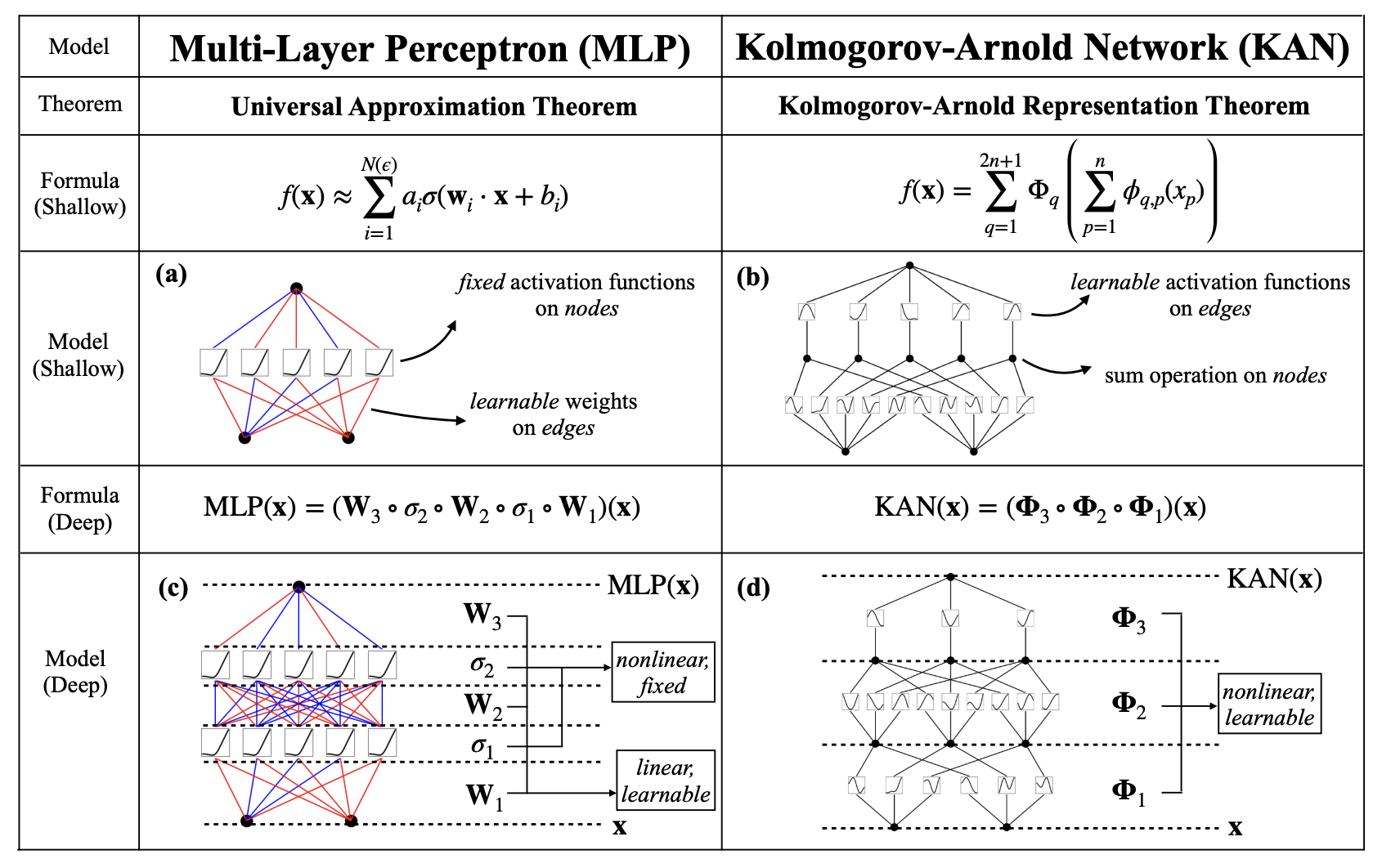
Comparison KAN vs. MLP [14]
KANs maintain the fully connected structure of MLPs. But while MLPs place fixed activation functions on nodes, KANs, on the other hand, place learnable activation functions—1D functions parametrized by a spline (functions defined piecewise by polynomials)—on weights and do not use any linear weights. The nodes in a KAN network simply add these 1D splines together, not adding any additional non-linearity. KANs can be viewed as a sweet spot between splines and MLPs, each harnessing their strengths to counterbalance their weaknesses. Splines are precise for low-dimensional functions but struggle with the curse of dimensionality (COD). On the other hand, MLPs perform well in high-dimensional contexts due to their feature learning capabilities (identification of patterns, structures, and characteristics from raw data). However, MLPs are less precise than splines in low-dimensional scenarios because they are not optimized for univariate functions. Thus, KANs excel in both aspects: they learn the external degrees of freedom (compositional structure) and also accurately approximate the internal degrees of freedom (univariate functions) [14]. See a comparison of KANs and MLP in the image above.
The paper shows that this results in better performance on a set of data fitting and partial differential equation exercises, and better interpretability by auto-regressively decomposing the function trained by the KAN into simple, easy-to-understand symbols. The researchers also published an API to construct, train, evaluate, and interpret KANs on your own. [16].
Person of the month: Sam Altman

Picture of Sam Altman [17]
Here, I want to talk about a person who inspires me a lot. I will even try to select a person I have personally met or at least seen during that month to make it a little more relatable and also share a little bit more about my life in the Bay Area. This month I would like to talk about Sam Altman.
Technically, this was not this month, but as part of this year's ETL lecture series at Stanford, I was able to see Sam Altman speak live in front of a bunch of students. This talk has been streamed on YouTube and watched hundreds of thousands of times, which is why I will not spend much time with holistic summaries of the talk. The most marketable lines like "Don't Care If We Burn 50B [to attain AGI]" have gone through the media a long time ago anyway. Instead, I will try to speak about why Sam Altman has been inspiring me for quite some time now and finally, try to pinpoint a few quotes that fuel this admiration.
Sam Altman was born in Chicago, US, in 1985. He grew up in Missouri where he went to a private school. After that, he started a Bachelor's degree in Computer Science at Stanford University, from which he dropped out after two years to found his first company, Loopt. After Loopt, an application to locate your friends, had trouble gaining traction, it was acquired for $43 million seven years after its founding in 2012. Loopt was also one of the first companies backed by the renowned Y Combinator program, which is why Sam agreed to join YC as a part-time partner after exiting his startup. In 2014, the legendary Paul Graham asked Sam to take over as the president of YC, which he accepted. Over the next five years, with Sam as president, YC excelled and invested in over 1,900 companies, including Airbnb, DoorDash, Instacart, and Reddit. In parallel to that, Sam co-founded OpenAI with Elon Musk in 2015. After Musk's attempt to step up as the CEO of the company in 2018, which Sam Altman did not allow, Musk left the company. In 2019, Sam Altman was named CEO of OpenAI and worked for the company full-time. We all know the rest of the story. OpenAI went ahead and revolutionized the world of AI with the release of GPT-3.5 in December 2022 and a bunch of other products such as DALL-E, Sora (soon), and the GPT-4 web application (soon) [22]. In November 2023, the board of OpenAI, which had a complex company structure balancing between for-profit and non-profit, announced it had fired Sam Altman as "it lost confidence in his ability to lead the company". After only one week and almost the entire OpenAI staff (around 98%) threatened to leave the company if Sam would not return, Sam Altman was put back in charge at OpenAI.
Now we have a broad idea of who Sam Altman is and what he does. Let's come to why he is an inspiration to me. The reason for this is three-fold:
- True Entrepreneur: Sam Altman lives for entrepreneurship. Having founded multiple ventures, overseen hundreds of companies at Y Combinator, and invested in some of the most successful startups ever, Sam Altman is a true entrepreneur. What I like about his point of view on entrepreneurship is its unbound simplicity. Unlike most entrepreneur coaches or lecturers, Sam will not give a speech about the heuristics to success as an entrepreneur but rather just let you build something and figure it out along the way. At ETL, when asked what one should do to be a good entrepreneur and how to know when it is the moment to jump, Sam answered, "nothing can teach you entrepreneurship, you just have to go for it." Sam's approach is probably as easy as that: start small (try to capture the "smallest possible cohesive subset of your market with users who desperately need what you are doing"), move fast ("Move faster. Slowness anywhere justifies slowness everywhere."), and listen to your customers ("Customer love is all you need").
- Versatile Generalist: At ETL, Sam advocated, "be good at a variety of things rather than being very good at one thing." Advising hundreds of companies building various kinds of businesses at Y Combinator, Sam Altman could be considered a generalist himself. But exactly this versatility helped him learn about many different industries and technologies, knowledge that helps him in his everyday life as a CEO as he leverages his cross-field knowledge to quickly understand problems and come to the best solutions. Nowadays, in a world in which economies of scale seem to be the most important rule, many think being very good at one thing is the way to go. One can capitalize on economies of scale, capturing value in a very specific domain in which you are better than everyone else, and leave every other domain to people who specialize in that respective field. Sam Altman does not agree with such a world of silos. Silos are a great way to move very quickly in a certain direction, but it is almost equally important to connect the silos with each other, making sure the overall direction in which you move is the right one. Exactly this is done by generalists. With a rather diverse set of interests and skills myself, this is a big inspiration to me.
- Firm Techno-Optimist: Sam Altman has incredible conviction in creating Artificial General Intelligence (AGI) for the benefit of humanity. His position as the CEO of OpenAI is not driven by financial incentives (he holds no equity in OpenAI). Instead, Altman is motivated by a profound belief in the transformative potential of AGI to benefit society. He mainly envisions AGI as a productivity tool that can help solve some of the world's most pressing problems, from healthcare to education to climate change [28]. His commitment to this mission is unbounded, as his take on the cost of AGI above underlined. For Sam, one of the most important factors in developing AGI is, as he mentioned at ETL, to "ship often and early" to allow society to adapt to emerging technologies and provide governments the necessary time to establish precise regulations. Altman’s motivation could be summarized in the techno-optimist manifesto, where innovation is harnessed for the greater good. This genuine desire to solve the world's problems through technology makes him a true inspiration.
Quote of the month

Quote of the month [29]
I do not want to get philosophical with this section but rather force myself to jot down the few quotes that resonate with me when I see them pass by. Not just because it's always a flex when you have a quote to drop every now and then, but because I find quotes very charming. They break down quite deep and complex facets of human beings in just a few words.
This month's quote is arguably the reason you are (in case you made it this far) reading this. I would consider myself more on the 'overthinker' side of things, meaning I tend to think a lot before actually doing something. It's probably not the worst habit to put some thought into what you are going to do next, but I tend to overdo it. What's this and that person going to think about me when I do that? How will it impact any stakeholders of that situation? Is there a scenario in which this could go wrong? Is the effort worth the risk? What are the opportunity costs? Do I really want this? and many more are questions that might cross my mind. The fact is, and that is where this quote hits the nail on the head, you cannot always be liked by everybody. You cannot always make it right for everyone. To go even further, most people do not even care about what you do or spend even a second thinking about you. And do not get this wrong, this is not an objection but just normal. I do not spend my days thinking about everybody I meet and see. Some time ago I read the excellent book "The Subtle Art of Not Giving a F*ck", which dives much deeper into this topic. Unfortunately, I have never internalized its main message: "Stop caring so much about what others might think but start thinking about what makes you happy."
This quote brought back exactly this thought and I will try to take it more literally this time. Who knows, maybe it also helps someone out there :)
Deep dive: AI Interpretability
The chances that a day has passed since the beginning of 2023 without me hearing the word “AI” are close to zero. Sure, one could argue that I study Data Science and currently live in the Valley, but no one can deny that the buzzword is omnipresent in today’s world. To give you a sense of recent developments, today, 77% of devices in use leverage some kind of AI, and the AI market is expected to grow with a CAGR of 42% to $1.3 trillion in 2032, about half of the GDP of France in 2022. Publicly, AI is always coupled with security concerns and risks. While there is good reason to believe that this technology is of unprecedented power, one might argue that a lot of the fear of AI systems comes from the lack of expertise on how these systems actually work, which makes it hard to understand their limitations. For instance, one of the godfathers of AI, Yann LeCun, Chief AI Scientist at Meta, recently addressed AI security concerns with: “before “urgently figuring out how to control AI systems much smarter than us" we need to have the beginning of a hint of a design for a system smarter than a house cat”. What, at least in my perception, is relatively little discussed is the fact that even the AI researchers at OpenAI, FAIR, DeepMind, and co. do not really understand how certain AI models work themselves. This does not mean that these researchers do not understand what they are doing (which they obviously do) but goes back to the conundrum of the interpretability of today’s predominantly used set of AI models, so-called Deep Learning models.

Mimicry of AI scientists wondering how deep neural networks work
But what does interpretability even mean in the context of the AI model? How does interpretability differ from explainability? Unfortunately, academics have not agreed on a specific difference between the terms or their differences yet. Generally speaking, the field of explainable AI (XAI) deals with understanding AI models’ inner workings in order to explain model outputs based on their input. The exact difference between interpretability and explainability leaves room for interpretation. Recently, scientists have started to draw the line based on the scope of the task. In this school of thought, explainability describes the capability to explain the reason for certain predictions to humans/users, while interpretability deals with understanding the inner workings of the model [34][35][36]. From my point of view, AI interpretability is necessary to reach explainability, which is why I will use this term predominantly.
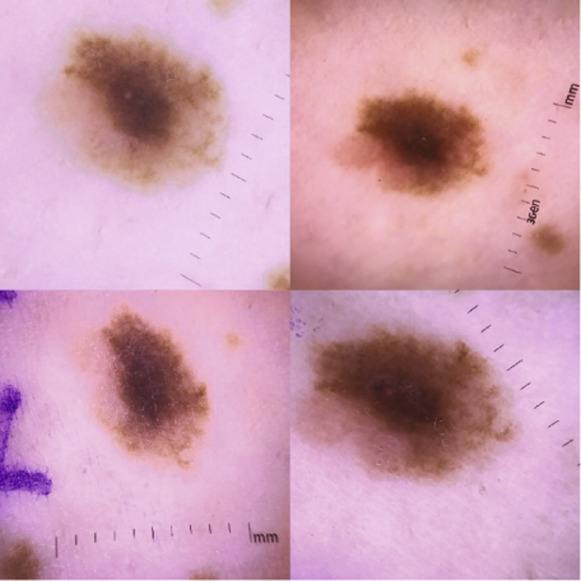
Multiple scans from the study mentioned above. Ruler is clearly visisble (see bottom right)[37]
This definition is all well and good, but why is AI interpretability even important? Let me try to give you an example and outline a few business implications of (the lack of) AI interpretability. Not too long ago, researchers at Stanford thought they had found a CNN-based classification model able to accurately detect signs of cancer based on skin images [37]. It turns out that the model was trained on a dataset in which a ruler (see image above), measuring the size of the malignants, was included in every picture of a cancer-causing malignant. Thus, the model just “learned” to detect a ruler at the border of the picture instead of actually learning how to differentiate between cancer-causing and non-cancer-causing malignants. If the researchers had not found this mistake and the model had been deployed into production, there is a good chance that patients with cancer-causing malignants would have been diagnosed cancer-free, wasting precious time to combat the cancer cells, potentially causing death. Sure, this example might not seem scary, yet it underlines the risk of not actually understanding how deep learning models reason. And with AI taking over the world, being implemented in more and more applications, AI models might soon make lots of decisions with direct impact on human life.
- Does your car turn left or right (Automobile)? Do you need more drugs to combat a certain disease (Healthcare)?
- Will you get a credit from your bank (Finance)?
- Will you get the job (Professional services)?
Next to risks, AI interpretability is also a major roadblock for a plenitude of business opportunities. A lot of industries such as Healthcare, Legal, and Automotive ask (regulatory) for human-in-the-loop applications of AI models (humans are part of the decision-making process and validate/authorize outcomes) because of the high stakes of every decision, limiting AI usage to worse-performing interpretable AI models. Moreover, fully interpretable AI models would not only open up business opportunities but also allow researchers and developers to excel in their work. For example, doctors could understand which symptoms allow computer vision models to detect lung cancer, potentially leading to new findings, advancing the combat of lung cancer, or developers could debug their AI applications systematically by understanding where errors stem from.
In the scientific world, AI interpretability has recently gotten a lot of attention. This is mainly due to the advent of the so-called black-box model. As implied before, not all AI models are interpretable by default. In so-called white-box models such as linear regression (including regularization techniques), decision trees, and generative additive models, the relationship between input and output is often linear and monotonic (the relationship between feature and label is one-directional) and always allows the decision-making process to be traced back from the prediction to the input [38] [39][40]. In black-box models, first and foremost deep neural networks (DNNs), however, we have highly non-linear, non-monotonic relationships between the input and output. In DNNs, these non-linearities are introduced by non-linear activation functions on the nodes (ReLU, GeLU, tanh, etc.). In combination with the large scale (billions of parameters) of today’s AI systems, driven by the ‘scaling laws’ of the transformer architecture, the results of these black-box models are uninterpretable for researchers and experts. Since this latter class of models, which includes all kinds of deep learning models (MLP, RNN, CNN, GAN, AE, GPT, ViT, diffusion models), support-vector machines, and others, is primarily used in practical applications due to their significantly better performance than white-box models, a lot of new methods have been introduced in the field of XAI lately, making it hard to cluster the field in a mutually exclusive collectively exhaustive structure. The best taxonomy I have found comes from a group of researchers from South Korea, Spain, and Egypt [36].
- Scope-based: The scope of the interpretability is one of the most common differentiations. We divide methods into local and global interpretability.
- Global interpretability: Interpretability for the entire model. Global interpretability means one can explain how the entire model reasons, from input to output. One approach to better understanding model reasoning is to isolate features to examine how marginal changes in these features impact the final prediction. The two prevailing methods to do so are partial dependence plots (PDP) and accumulated local effects (ALE). PDPs map the values of one or two features to the output value by marginalizing the remaining feature space [41]. ALEs describe the average impact of a feature on the final prediction by averaging over the change of prediction in a small window [41]. ALEs are preferred in many applications as they are unbiased for correlated features, which occur often in real-world datasets. Another important global interpretability concept is feature importance. While there are many different heuristics to compute the feature importance, the basic idea is to attribute a relevance weight to each input value according to their “impact” on the final prediction. A popular feature importance method is permutation feature importance where single features are permuted and feature importance is deduced from the following change in the prediction error.
- Local interpretability: Interpretability for a specific data sample. According to our previous definition, we could also speak about local explainability in this case. Local interpretability means one can explain why for a specific input, the model outputs a specific output. One way to gain local interpretability is to locally train a white-box model, a so-called surrogate model, to explain an individual prediction. Most commonly, we use Local interpretable model-agnostic explanations (LIME) to do so [42]. We can then leverage the interpretability of the interpretable model trained to “learn” the behavior of our black box to get an idea of local decision boundaries, feature importance for specific predictions, and perturbations.
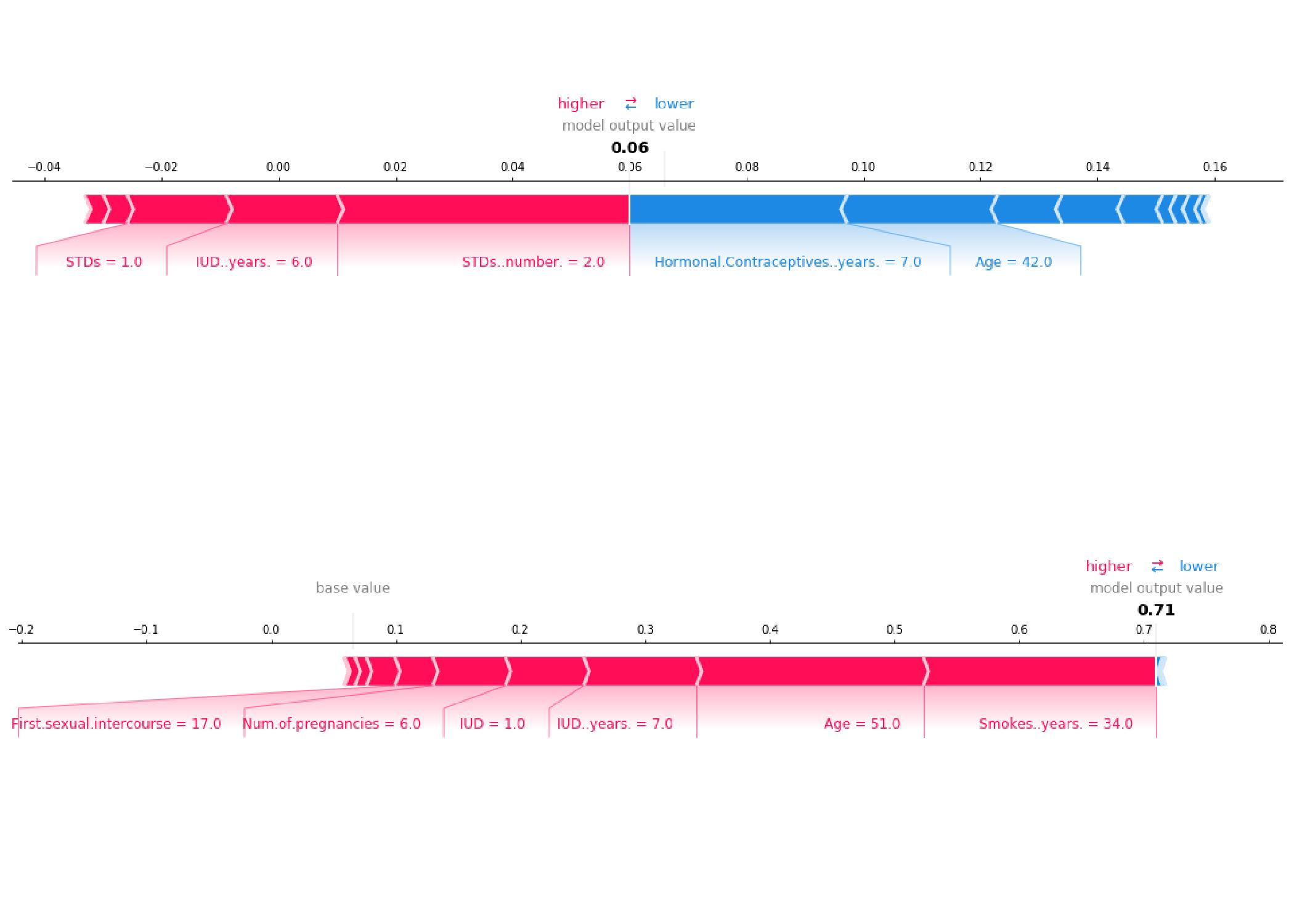
Example for local interpretability via SHAP values for prediction of risk for cervical cancer[41]
- Model-based: We divide methods into model-specific and model-agnostic methods.
- Model-specific: On the one hand, there is a wide variety of AI architectures out there. Some of these architectures will allow dedicated interpretability methods to yield better interpretability. These methods are called model-specific methods. One of the most broadly used model-specific methods is attention scores/maps. Transformers, probably today’s most used AI architecture, work so well because they allow weighing the importance of other input according to their relevance and using this weighted input as context for the current prediction. This is done through the matrix multiplication of a query (”What is relevant for the current prediction?”) and a key (”What does this input have to offer?”) embedding, which results in an attention score used to weigh the inputs. These attention scores, by definition, shed some light on what inputs the model deems important in its prediction process, similar to other local feature importance interpretability methods. For computer vision models, these attention scores can be displayed as attention maps, highlighting which pixels in the image got the most attention for a specific prediction. While this method has only limited application in state-of-the-art architectures due to the use of MLP layer, it has been shown that transformer-only models are practically white-box models as they can be written as a sum of interpretable end-to-end functions [43].
- Model-agnostic: On the other hand, we need model-agnostic interpretability methods to compare the interpretability results of different models with each other. Furthermore, these methods give developers and researchers flexibility in the choice of their model. An example of a model-agnostic method that has recently gained a lot of popularity is SHAP values (SHapley Additive exPlanations). The idea behind SHAP values, originating from cooperative game theory, is to attribute “credit” to the input features, building a SHAP feature importance score. SHAP value expresses the contribution of the features to get to the current output f(x) from a base value E[f(z)] that would be predicted if we did not know any features (see image above) [44]. One of the main advantages of SHAP values is that they are additive, meaning that the contribution of each feature adds up to the total contribution of the features, yielding comparability between features. SHAP values can be used for all kinds of models. While the concept is designed for local interpretability, there are also modified versions used for global interpretability.

Example for attention scores based on translation task. One can see that attention scores are higher for articles and verbs since these are relevant context for correct translations[45]
- Complexity-based: As mentioned before, from an interpretability point of view we can divide models into two clusters, white-box and black-box models. For each of these clusters we use different interpretability methods. We divide methods into intrinsic and post-hoc methods.
- Intrinsic: Some might argue intrinsic interpretability is not even an interpretability method. For methods in this cluster, interpretability is already built into the model as, for example, it is the case for linear regression models. Next to white-box models, researchers have also tried to alter the structure of black-box models to make them intrinsic. We already talked about the interpretable transformer-only architecture. Another attempt to make black-box models intrinsically interpretable revolves around concept-based interpretability. Concepts, in this context, are high-level, human-understandable units of information. The idea to define and evaluate models based on concepts stems from computer vision. For instance, in computer vision models trained to classify animals one could introduce the presence of fur, the height of the animal, and the number of extremities of the animal as concepts. The two prevailing methods to make models interpretable using concepts are Concept Bottleneck Model (CBM) and Testing with Concept Activation Vectors (TCAV). The earlier method, CBMs, (see image below) includes introducing an intermediate model, a context predictor, into the original model to learn if human-defined contexts are fulfilled for the input, and based on the fulfillment or lack of fulfillment of the concept layer, the model predicts its output [46]. The latter method is rather global and model-specific but will be mentioned for completeness. TCAVs learn concept activation vectors from the node activation in a certain layer of the network based on a comparison of the activation in training samples with the defined concept versus training samples without this concept. This way we can model the decision boundaries of these concepts to get a better idea of the global reasoning of the model [47]. While earlier methods rely on human-defined concepts in a supervised setting, there are first semi-supervised and unsupervised approaches to let the model “learn” significant concepts by itself.
- Post-hoc: As we discussed before, black-box models are not interpretable by definition. To make this kind of models more interpretable we often use post-hoc methods, which often imply training a second, so-called surrogate model, to explain predictions of the original black-box model. Most of the methods that we have discussed previously such as SHAP, PDP, ALE, LIME, TCAV, and many more are actually post-hoc methods which is why I do not see the need to dive into another example at this point in time.
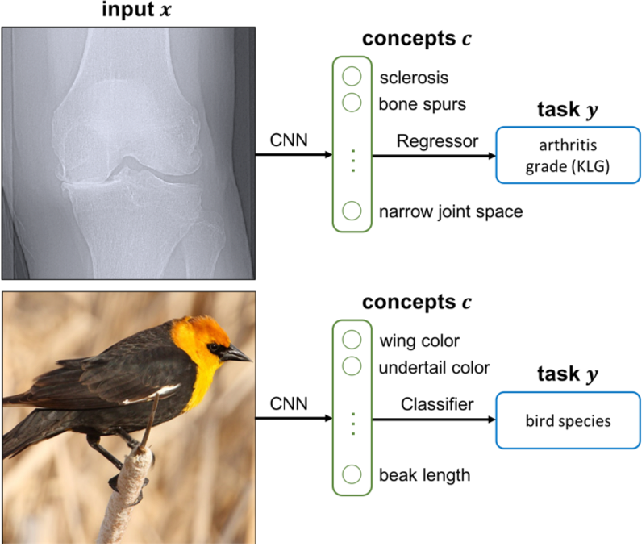
Example for concept bottleneck model. Model is "bottlenecked" by human-understandable concepts to comprehend decision-making process[48]
- Methodology-based: Last but not least, over time, researchers have found different approaches to solving the interpretability problems of AI models. It is also possible to distinguish methods according to their family of approach. Most of these approaches fall into the cluster of model-specific interpretability methods for deep neural networks. This includes but is not limited to [36]:
- Backpropagation-based methods: In supervised learning, deep neural networks learn to optimally map inputs to outputs by continuously updating their parameters according to a loss that captures the deviation between the prediction with the old weights and the true prediction. This update of the parameters, called backpropagation, is done gradually backward from the output to the input leveraging Leibniz’s chain rule to adjust each weight according to its “contribution” to the final prediction. Interpretability methods like “Layer-wise relevance propagation” try to use a similar approach to recursively reconstruct the contribution of each input node to the final output. To do so, the method assumes that each layer weighs the inputs coming from the previous layer with a certain relevance, which is equal for each layer. This relevance can be deduced from the weights on the edges between the layers using Deep Taylor Decomposition and projected from the output back onto the input through backpropagation [49].
- Perturbation-based methods: In perturbation-based methods, the sensitivity of the model to changes or masking (”perturbations”) of inputs and model parameters is inspected regarding the impact on the output by comparing old and new input values with each other. Methods include, for example, applying grey masks to parts of the input images in computer vision tasks or the change of words in the text input of an NLP model. This cluster also includes adversarial methods in which small perturbations that cause false predictions are explored to map decision boundaries [41]. A major downside of these methods is their compute intensity.
Honorable mentions: There are a bunch of other interpretability methods that I did not discuss above. Feel free to check them out. Saliency maps [50], BagNets [51], TED [52], SENN [53], and DkNN [54] to name a few.
Last but not least, we want to have a quick look at interpretability methods for the type of models that are probably the most relevant in AI right now, namely models powered by generative pre-trained transformers (GPTs), such as LLMs like ChatGPT, Gemini, LLaMa, Claude, and others, and vision transformers. Since Transformers are based on the attention mechanism, one might think they can be analyzed using attention maps as mentioned under 2.1. Unfortunately, GPTs are far from following transformer-only architectures. With today’s scale, GPTs easily include up to 100 or more layers of multi-head attention heads. Furthermore, these attention heads and other parts of the GPT architecture rely on MLP layers, which come with their inherent black-box characteristic, making it hard to propagate attention scores from one end of the network to the other. While attention mechanisms and feature attribution (backpropagation- or perturbation-based) can shed some light into the dark [55], pioneering research institutions like OpenAI and Anthropic recently started advocating for mechanistic interpretability [56][57].
Mechanistic interpretability is a bottom-up strategy that encompasses making the smallest components of neural networks interpretable to be able to scale this interpretability to the largest networks, similar to reverse engineering (think of software reverse engineering).
Although there have not been any major breakthroughs in the field yet, recent publications around circuit interpretability look promising. The idea of deep neural networks having similar structures as biological organisms is trivial, after all large parts of neural networks stem from insights in neurology. But visualizations of the latent spaces of computer vision models have exposed a glimpse into the rich inner world of DNNs. In the paper “Zoom In: An Introduction to Circuits” [57], published by OpenAI researchers in 2020, researchers found that in the InceptionV1 model, a rather simple CNN model for image classification, groups of nodes in certain layers seem to “learn” to detect characteristics in the input pictures during the training process. For example, a group of neurons in an early layer learned to detect curves in the input pictures (see image below) while another group of neurons in a later layer learned to detect dog snouts. Further examinations, e.g., for the first example, show that lighter curves lead to lighter activation of the neurons and that the rotation of the curves leads to a shift of the activation inside the group of neurons which showed to capture curves at all angles, ruling out the chance of a coincidence. Based on these findings, the concepts of:
Features: fundamental units of neural networks
Circuits: features connected by weights
were introduced. More complex features, e.g., cars, can be thought of as aggregations of downstream features, e.g., tires and windows, through circuits. Positive weights between features indicate that the latter feature (client) is excited when the prior feature fires, and negative weights indicate the client is inhibited when the prior feature fires. Unfortunately, researchers have also found the phenomenon of polysemantic neurons, neurons deliberately combining different features without any rationale, which still cannot be explained [58]. On another note, researchers at OpenAI, as a part of their goal to ‘Training AI systems to do alignment research’ [59], have introduced a new technique to accelerate the advancements in AI interpretability. In a 3-step process, researchers prompted GPT-4 to explain the behavior of model weights in the GPT-2 model and to score the explanation [60]. The researchers admitted that the method was not performing very well, yet saw promising improvements with better models and additional prompting.
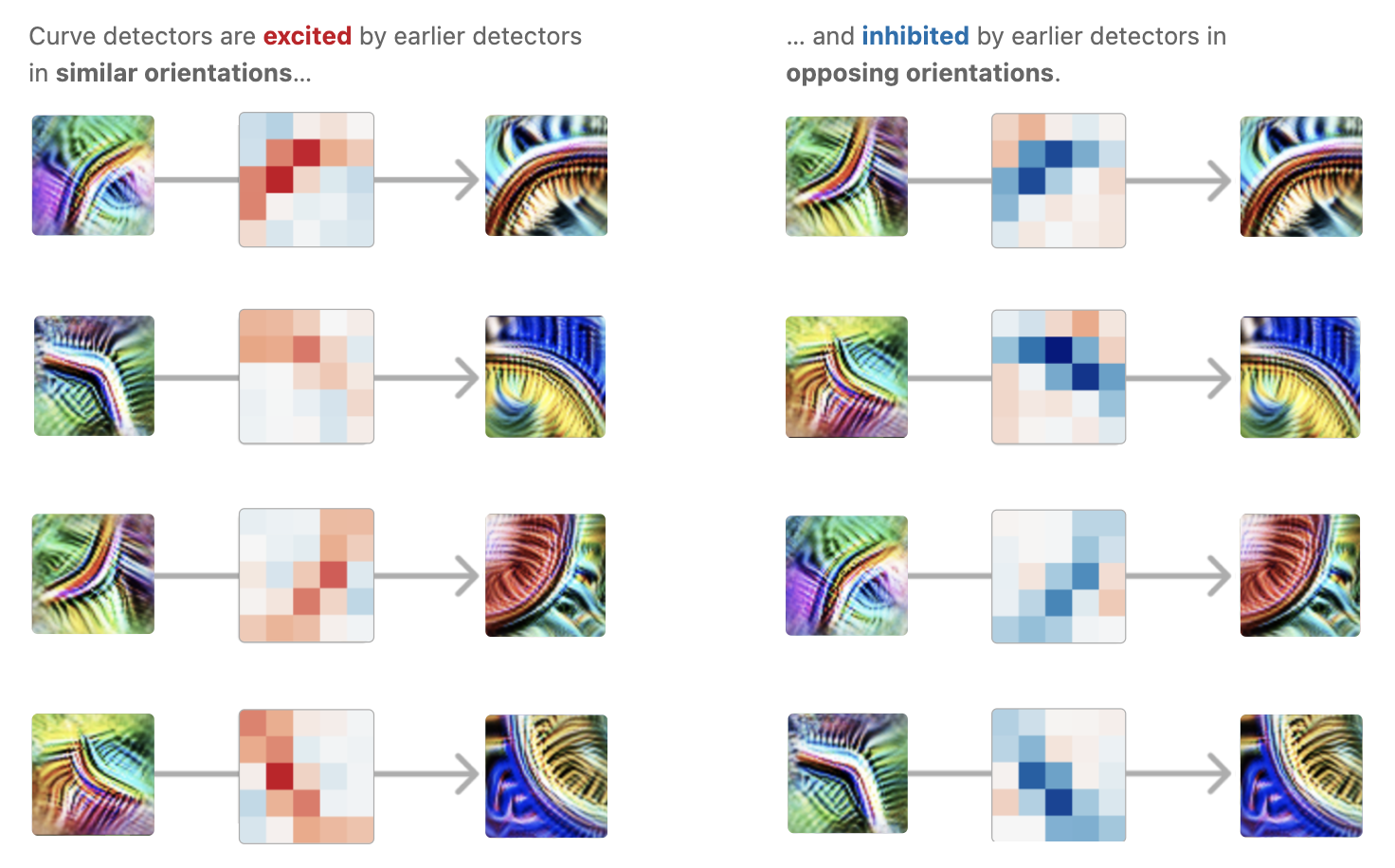
Example for circuit in mechnistic interpretability. In lower layers of the CV model a circuit learned to detect curves. As mentioned it detect cruves in all orientations and even captures their magnitude[56]
To conclude, the lack of interpretability remains one of the biggest issues of deep neural networks. Not only does the black-box characteristic of these models impede advancements in model performance but it also prevents the implementation of this powerful family of models for many applications, including law, healthcare, and automotive. As researchers intensify research on the interpretability of GPTs, the area of mechanistic interpretability looks promising, even though lacking generalizable results.
References
- Artisan AI.
- Jaspar Carmichael-Jack LinkedIn Profile.
- Sequoia’s AI Ascent.
- H Company.
- Kyle Vogt's Twitter Announcement.
- The Bot Company
- Langfuse.
- Langfuse tracing example
- Analytics.
- Prompt management.
- Playground.
- Evals.
- Datasets.
- KAN: Kolmogorov-Arnold Networks Paper.
- Kolmogorov-Arnold theorem.
- KANs as two-layer networks.
- Picture of Sam Altman.
- Sam Altman's Twitter Profile.
- Sam Altman's Talk at Stanford ETL Lecture Series.
- Y Combinator.
- OpenAI.
- Biography of Sam Altman.
- CNBC Article on Sam Altman's Firing.
- Smallest possible cohesive subset.
- Move faster.
- Customer love.
- Forbes Article on Sam Altman.
- CNBC Article on Sam Altman's Views on AGI.
- Stop trying to be liked by everybody.
- "The Subtle Art of Not Giving a F*ck" by Mark Manson.
- Authority Hacker AI Statistics.
- Bloomberg Generative AI Market Report.
- Yann LeCun's LinkedIn Activity.
- TechTarget on Explainable AI (XAI).
- Wikipedia on Explainable Artificial Intelligence.
- ScienceDirect Article on Taxonomy of Explainable AI.
- Stanford Study on CNN-Based Cancer Detection.
- Black box vs. white box models.
- White-box machine learning explained.
- Black-Box vs. White-Box.
- Interpretable Machine Learning Book on Partial Dependence Plots.
- LIME: Local Interpretable Model-agnostic Explanations Paper.
- Transformer Circuits Framework.
- SHAP: SHapley Additive exPlanations Paper.
- Attention scores in NLP translation tasks.
- Concept Bottleneck Model (CBM) Paper.
- Testing with Concept Activation Vectors (TCAV) Paper.
- Concept Bottleneck Models
- Layer-wise Relevance Propagation Paper.
- Saliency Maps Paper.
- BagNets Paper.
- TED Paper.
- SENN Paper.
- DkNN Paper.
- Rethinking Interpretability in the Era of Large Language Models.
- Transformer Circuits Interpretability Dreams.
- Zoom In: An Introduction to Circuits Paper.
- A Mathematical Framework for Transformer Circuits.
- OpenAI Approach to Alignment Research.
- OpenAI on Language Models Explaining Neurons.